昨天最後面有留一題練習題,不知道你們做得怎麼樣拉?如果有某些地方卡住也沒關係,理論到實際操練本來就會有一些差距,而且新手們一定對於程式碼指令還不是太熟悉,所以OK的OK的!
那今天我會分享我自己的解法讓你們參考看看!
提醒一下,我們這裡只做類似training的動作,因為資料是我隨意打的,所以數量只有10筆,再切成train和test可能會效果不佳。所以我們的目標是利用這10筆資料去找到那個最佳的函式(model),並且把它畫出來!
下圖JOHN國的房價,JOHN國的房價很簡單,只受到坪數大小的影響。
id | price | sqft_living
------------- | ----------
1 | 500000 | 55
2 | 275000 | 27
3 | 360000 | 33
4 | 780000 | 70
5 | 145000 | 13
6 | 280000 | 26
7 | 860000 | 89
8 | 200000 | 21
9 | 90000 | 10
10 | 680000 | 67
因為只有10筆資料,且我不是給csv檔案,所以我們必須手動輸入摟!
import numpy as np
import matplotlib.pyplot as plt
data_x = np.array([55,27,33,70,13,26,89,21,10,67])
data_y = np.array([500000,275000,360000,780000,145000,280000,860000,200000,90000,670000])
plt.plot(data_x,data_y,'o')
輸出: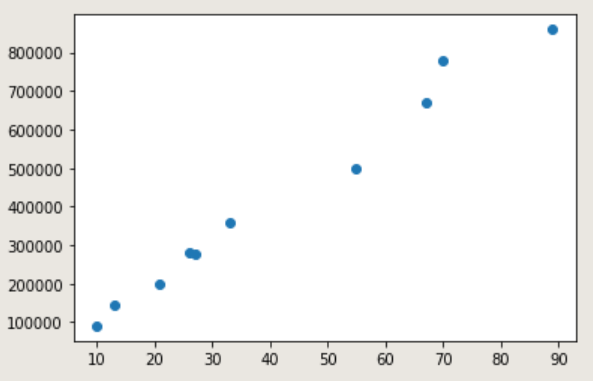
將視覺化資料後,可以看出來所有的資料似乎是線性的關係,也不會有太多的彎曲,所以假設很簡單的函式池子:y = w * x + b。
1.先定義出填入資料的空間xs、ys,使用到tf.placeholder騰出空間,方便後來將資料填入,所以xs、ys是放入data_x和data_y的地方。
2.令兩變量weights、biases,利用tf.random_norma()使weights是一個1*1的矩陣的隨機初始值,而biases則是先設定初始值是0。
3.然後定義出 y = weights * xs + biases 的函式池子,且這邊的y將會是預測值。另外,因為weights和biases會一直變動,所以y也會一直變動,下一步會利用y的變動和真正的y(price)之間的差和用最小平方法調整loss並得到最好的weights、biases)。
import tensorflow as tf
#定義資料空間
xs = tf.placeholder(tf.float32)
ys = tf.placeholder(tf.float32)
#定義權重與偏差
weights = tf.Variable(tf.random_normal([1]),name = "w")
biases = tf.Variable(tf.zeros([1]), name="B")
y = weights*xs + biases
先介紹下:
1.tf.reduce_mean():就是用來計算平均值。
語法:reduce_mean(input_tensor,axis=None,keep_dims=False,name=None)
分別是(1)輸入的tensor(2)指定的軸(3)是否下降維度(4)名稱
2.tf.square():前面有提到哦,平方用的。
語法:tf.math.square(x,name=None)
分別是(1)輸入值(2)名稱
3.tf.train.GradientDescentOptimizer():建立梯度下降的優化器。
語法不特別介紹,通常裡面只放學習率就好。
4.optimizer.minimize():用來找到最小的loss。
語法不特別介紹,裡面放要下降的參數。
再來這些運算的概念可以從這邊開始參考:【Day 05】超級基礎的機器學習-Linear Regression 介紹(2/2)
在做這個練習的時候,我也只有把原本教學的MAE改成MSE(Mean-Square Error)而已,原本的取絕對值改成取平方,其實道理是相同的,都是取正值!
## 損失
loss = tf.reduce_mean(tf.square(y - ys))
## 優化
optimizer = tf.train.GradientDescentOptimizer(0.0001)
train = optimizer.minimize(loss)
這邊我直接在程式碼中註解即可,比較好了解。
init = tf.global_variables_initializer() ##初始化(前面有提到variable一定要做這個動作哦~)
with tf.Session() as sess: #tensorflow常用的起手式
sess.run(init) #tf的東西一定要run才會動
for step in range(20): #疊代20次
print(step, sess.run(weights, feed_dict={xs:x_data, ys:y_data}), sess.run(biases, feed_dict={xs:x_data, ys:y_data}))
#先查看初始值
sess.run(train, feed_dict={xs:x_data, ys:y_data}) #將data匯入,啟動優化器,開始更改weights和biases
pred = sess.run(y, feed_dict={xs:x_data, ys:y_data}) #把預測值一併算出來
plt.plot(x_data, pred) #畫線
plt.plot(x_data, y_data, 'o' ) #畫點
輸出: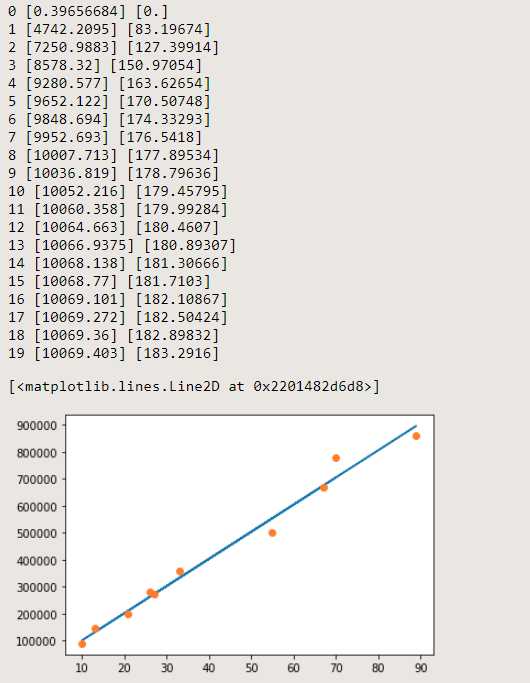
小結:因為訓練資料較少,所以只要疊代20次就可以了,也可以在15~19次時看出基本上不會有太大的改變了。
今天做了一次完整的線性回歸,也採用之前提過的梯度下降法,還有類似MAE的MSE,總算是有點感覺了吧!
明天會介紹另一個常用的訓練套件-keras!繼續努力囉~

